
How to use the Hub Component Repository¶
Principles¶
(See also Z2V2.1 is out – working on v2.2)
By default, a Z2 installation (a z2 Home) accesses the version controlled storage that holds the system definition directly to download and prepare (and compile) modules as needed. This is the underpinnings of the system centric, pull-deployment based approach. In some situations however, it is not desirable to have source code on production servers at any time. This may be for compliance reasons or for fear of risking theft of intellectual property.
This is where the HubCR comes in. As a principle, all modules, all component resources, essentially anything the Z2 runtime knows about is served by component repository implementations. There are implementations for Subversion, Git, file system folders, development workspaces and now, the latest addition, for another Z2 server that provides a consolidated, source-code free and pre-compiled view onto production resources (the HubCR provider).
So, instead of having production systems read and process source code directly, an intermediate node provides a semantically equivalent but pre-processed view onto the system definition:
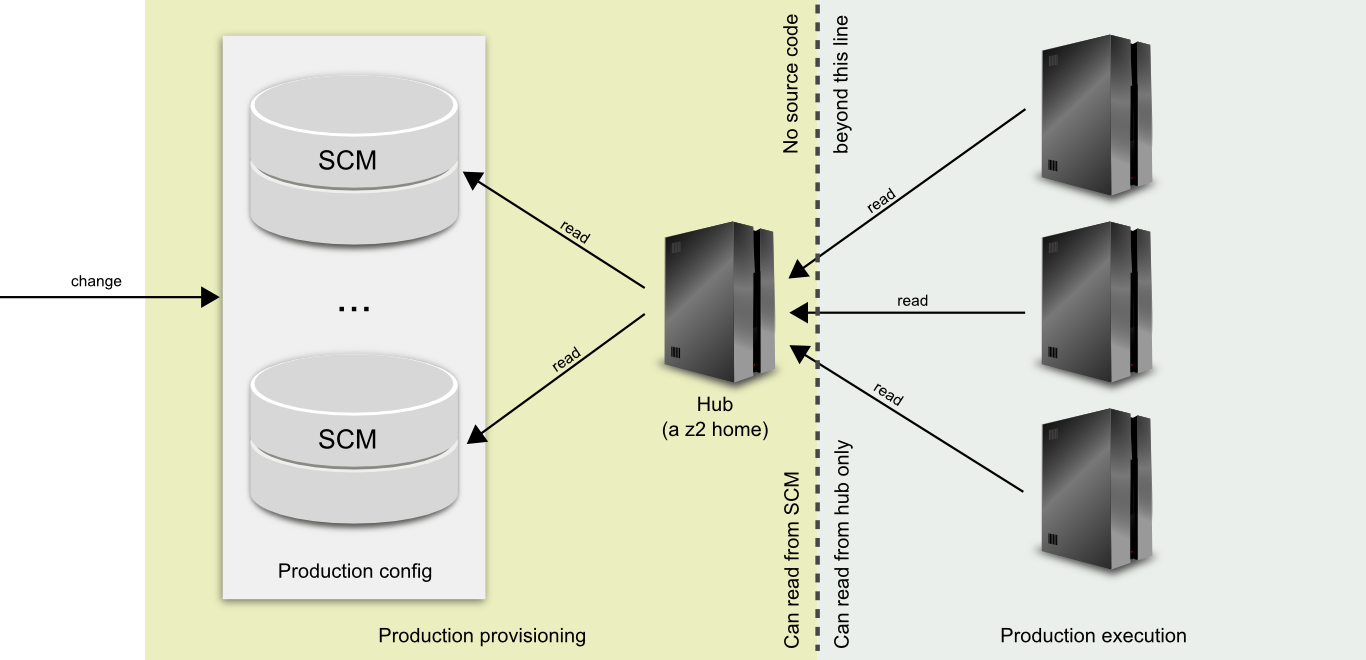
The way the HubCR does that is by maintaining a pre-compiled and source-code stripped snapshot of the original production configuration. At the same time, the HubCR is just a regular z2 Home that runs the production config.
To the real production nodes (on the right in the diagram) however, the HubCR presents everything but the HubCR and other remote component repositories.
As a result, production systems can be completely separated from the source level details of the system definition. They don’t even see authentication details to the configuration store – only those necessary to access the HubCR service. At the same time, the pull semantics are preserved and updates can flow in and will be distributed consistently as for any other Z2-based system.
How to configure and use¶
The HubCR consists of three parts:
- For once, there is a repository client implementation (part of the Z2 core, so that bootstrapping from a HubCR is possible).
- Secondly there is a z2-base level module that implements the serving side as a Web application
- and thirdly there are some important rules that allow to implement the HubCR in a system that can be used in the default development flow as well.
The latter is a crucial cool feature: Using a system with the HubCR (client) from where no access to the source repositories is possible (or desired) is just one special way of instantiating the system. The default way, connecting directly, still works at the time. So we can develop and test hot fixes within the system and only then roll out changes via the HubCR to production nodes.
Consuming from a Hub¶
In order to connect a z2 <home> to a HubCR, you simply configure a repository to read from as in all the other cases. A HubCR consuming declaration of com.zfabrik.boot.config/hubRepository.properties (see in particular How to create your own system to learn about repository topology) may look like this:
com.zfabrik.systemStates.participation=com.zfabrik.boot.main/bootrepo_up
#
# hub stored component repository
#
com.zfabrik.component.type=com.zfabrik.hubcr
#
# The URL to the source repo. Typically this is of the form http://<server>:<port>/z_hubcr
#
hubcr.url=http://myhub:8080/z_hubcr
#
# Connection timeout in ms for connecting to the providing side (defaults to 10000)
#
hubcr.timeout=10000
#
# The remote user to use (optional but required by default)
#
hubcr.user=hubcr_accessor
hubcr.password=admin
#
# The priority of the repository (defaults to 500)
#
hubcr.priority=500
A node using the HubCR to read its content will typically not connect to any other repository. So check carefully, if there are other effective repository configurations in Z2_HOME/run/local/com.zfabrik.boot.config.
Please visit in addition the ComponentRepositoryImpl javadocs.
Serving from a Hub¶
On the serving side, i.e. the node in the middle of the diagram above, the following configurations need to be applied:
- The Web application com.zfabrik.hubcr/web needs to be enabled, typically by a state dependency. This configuration needs to be applied in your system repository at (equivalently!) com.zfabrik.hubcr/web/z.properties (or - locally - in a dev repository)
- Secondly the operational configuration at com.zfabrik.hubcr/manager should be revisited. As above, this needs to be done in your system repository at (equivalently!) com.zfabrik.hubcr/manager.properties (or - locally - in a dev repository). Details are given in the Javadocs.
One important concept to understand is how new revisions of the contents the HubCR serves come into existence. It is important to understand that not every update in the repositories that are read from the HubCR server create a new revision for HubCR consumers. As the HubCR needs to provide a consistent view onto its repository content, regardless of when a consumer asks for a specific resource, the HubCR builds a complete repository content structure at specific points in time to be served to its clients.
There are two alternatives:
hubcr.scanOnSync=true¶
In that case, every synchronization of the HubCR serving Z2 updates the HubCR provided repository content. This procedure is simple and effective.
hubcr.scanOnSync=false¶
If you want to prefer synchronization of the HubCR server from the contents it provides to its consumers, you can choose to trigger updates of the HubCR content manually. Not however that the HubCR server still needs to be synchronized, as the HubCR content is a reflection of what the HubCR server itself sees as system content.
Updates on the HubCR repository content can be triggered from the (very basic) HubCR management interface (same login as /adm, user "z*" with password "z" by default) at http://<server>:<port>/z_hubcr:
Finally, the JMX MBean zfabrik:type=com.zfabrik.impl.hubcr.store.HubCRResource offers methods to check HubCR status and to trigger an update.
One system, many homes with different provisionings¶
This final section is on the important rules (you should be prepared for that by now) that make sure, it all plays out.
If the HubCR would reflect the contents of the repositories readable by the HubCR server faithfully - modulo pre-compiling and the removal of source code - all repositories, such as add-on repositories that we like to configure in the environment module, would show up in the stock of modules and components visible to HubCR consumers (right side of the diagram). If that would happen, the HubCR consumer would try to read from them after all (which is exactly what we do not want - besides the point that the HubCR already provides everything those other repositories can offer).
In order to prevent that, the HubCR manager config (as mentioned above and here) allows to specify name prefices and component types to filter out when preparing the HubCR content. The default is to filter all other repository types.
This way, consumers of the HubCR get a consistent view, without trying or requiring to access source-code repositories, while direct (you may say classical) consumers can still read from the source code repositories and see the system in its original glory as is the original promise of Z2.
Configuration summary¶
To sum things up, in order to configure the use of the HubCR, you need to:
- On every HubCR consumer home replace the base and scenario repositories (
com.zfabrik.boot.config/baseRepository.propertiesandcom.zfabrik.boot.config/scenarioRepository.propertiesresp.) by a single HubCR repository (com.zfabrik.boot.config/hubcrRepository.properties) as described in Consuming from a Hub. - Configure the HubCR Web app and manager in the module
com.zfabrik.hubcrin the your base repository (or - locally - in a dev repository) as described in Serving from a Hub.
Updated by Henning Blohm almost 13 years ago · 16 revisions