
Sample that combines HBase with full-stack Spring and Hibernate usage¶
This sample consists of an application that loads large Mbox archive files into HBase and extracts email addresses using a map reduce job. Extracted email addresses are then written to a relational database and offered for editing.
Being a full stack sample it shows how to design a multi-module application with a service tier that can be seamlessly used from a Web app as well as from an application-level map-reduce job.
Note: This sample still uses v2.2 of z2 - so making sure the correct versions are specified below is crucial.
Note: Due to HBase, you will need to run this on Linux or Mac OS.
Proceed to how this works, if you do not want to run the sample but only learn about it.
Note the
Z2 has the following Java Version requirements
| Z2 Version | Min. Java version required | Max Java version supported | Max language level |
|---|---|---|---|
| 2.1 - 2.3.1 | Java 6 | Java 7 | Java 7 |
| 2.4 - 2.5 | Java 8 | Java 8 | Java 8 |
| 2.6 | Java 9 | Java 11 | Java 10 |
| 2.7 | Java 9 | Java 11 | Java 11 |
| 2.8 | Java 9 | Java 13 | Java 13 |
| 2.9b | Java 8 | Java 8 | Java 8 |
| 2.9.1 | Java 11 | Java 16 | Java 15 |
| 2.9.1b | Java 8 | Java 8 | Java 8 |
| 2.10 | Java 11 | Java 18 | Java 18 |
| 2.10.1 | Java 11 | Java 21 | Java 18 |
| 2.10.2 | Java 11 | Java 21 | Java 18 |
| 3.0 | Java 17 | Java 23 | Java 23 |
| master | Java 17 | ? | Java 23 |
Note: Most samples suggest to use the master branch. You may choose another version branch (please check the respective repository).
Make sure you have a corresponding Java Development Kit (JDK) or Java Runtime Environment (JRE) installed. If in doubt, go to Download Java SE.
Note: Running v2.1-v2.3.1 on Java 8 is supported by specifying
com.zfabrik.java.level=7
(or 6, if that is your desired compilation language level) in <home>/run/bin/runtime.properties. By this the Java compiler version detection does not fall back to a lower level.
Install¶
Here is the quick guide to getting things up and running. This follows closely How_to_run_a_sample and Install_prepacked_CDH4.
Checkout¶
Create some installation folder and check out the z2 core and the HBase distribution, as well as the sample application.
git clone -b v2.2 http://git.z2-environment.net/z2-base.core
git clone -b v2.2 http://git.z2-environment.net/z2-samples.cdh4-base
git clone -b master http://git.z2-environment.net/z2-samples.hbase-mail-digester
(Note: Do not use your shared git folder, if you have any, as the neighborhood of these projects may be inspected by z2 later on).
Prepare¶
We need to apply some minimal configuration for HBase. At first, please follow Install_prepacked_CDH4 on how to configure your HBase checkout. There are a few steps that need to be taken once only but still have to.
Assuming HBase has started and all processes show as described, there is one last thing to get running before starting the actual application:
Running a Java DB Network Server¶
Previously to Java 9, the Java SE Development Kit (JDK) by Oracle provided the Java DB - essentially the same as the Apache Derby DB. That is not the case anymore. However, we use that Database implementation in our samples. In order to run those samples that illustrate use of a relational database, please follow the instructions below to install and run Apache Derby. Could hardly be simpler.
Step 1: Download and Install¶
Unless you have done so already, download Apache Derby DB and follow the installation how-to.
Note: You do not need to unpack Apache Derby into some global folder on your system. Instead you may want to use some local folder under your user's home folder. There is no problem installing and runnning different instances and configurations at any time.
Step 2: Run¶
Let's assume you installed (well - unpacked) into a folder $DERBY_INSTALL. Also, let's assume some Java Runtime Environment is installed and ready.
Simply run the following on Linux or Mac OS:
cd $DERBY_INSTALL
java -jar lib/derbyrun.jar server start
On Windows run
cd %DERBY_INSTALL
java -jar lib\derbyrun.jar server start
That's it. Apache Derby will be waiting for connections on port 1527.
Start¶
Now that all databases are up we can start the application simply by running (as always):
# on Linux / Mac OS:
cd z2-base.core/run/bin
./gui.sh
# on Windows:
cd z2-base.core\run\bin
gui.bat
At first startup this will download some significant amount of dependencies (Spring, Vaadin, etc.). So go and get yourself some coffee....
When started, go to http://localhost:8080/digester-admin. You should see this:
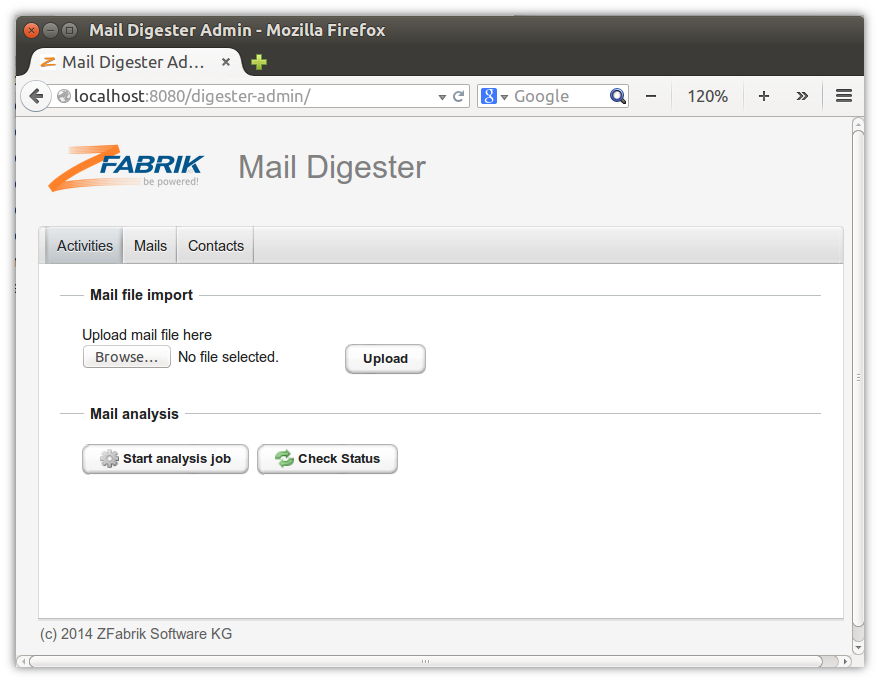
Using the application¶
To feed data into the application, please download some mail archive in mbox format, e.g. from http://tomcat.apache.org/mail/. Upload the file to the digester application as outlined on the first tab. Mails from mail archives are imported into the HBase database.
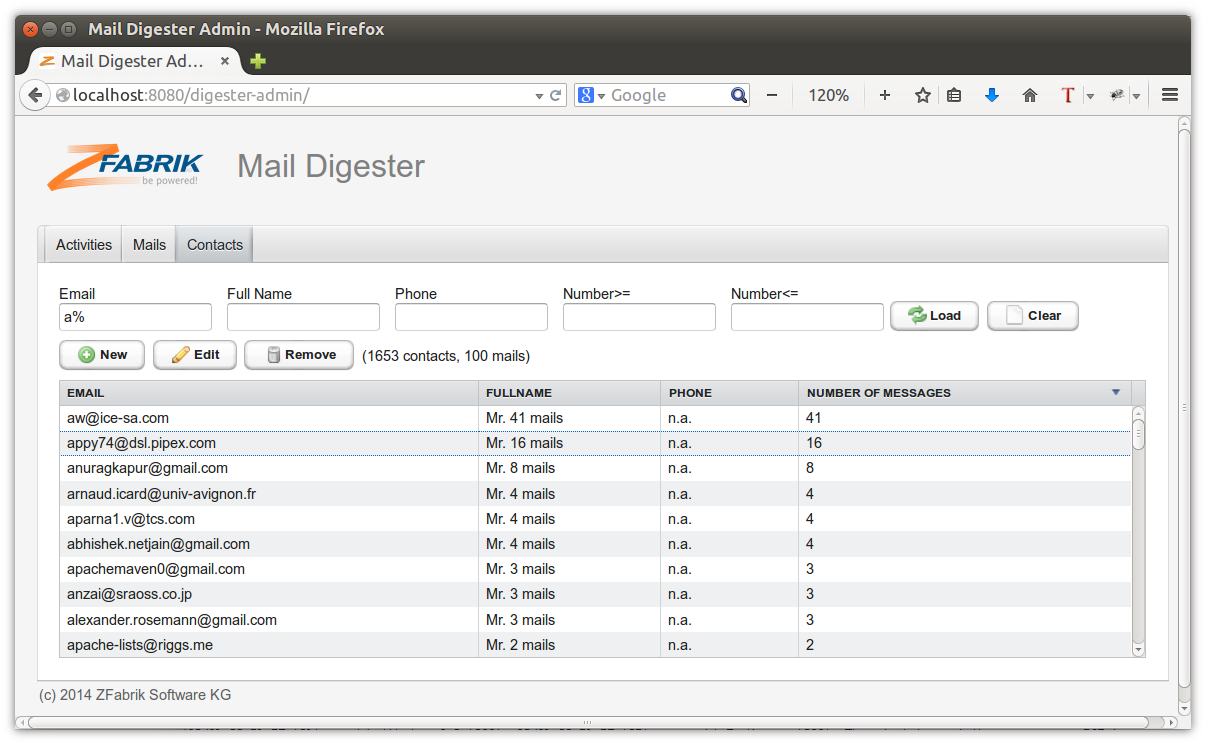
When imported, run the analysis map-reduce job by clicking on "Start analysis job". The purpose of this job is to identify mail senders and provide some data like email address, full name, and number of mails into the relational database powered by Derby.
When there is only little data in HBase, progress reporting is rather coarse-grained. After a while you should see:
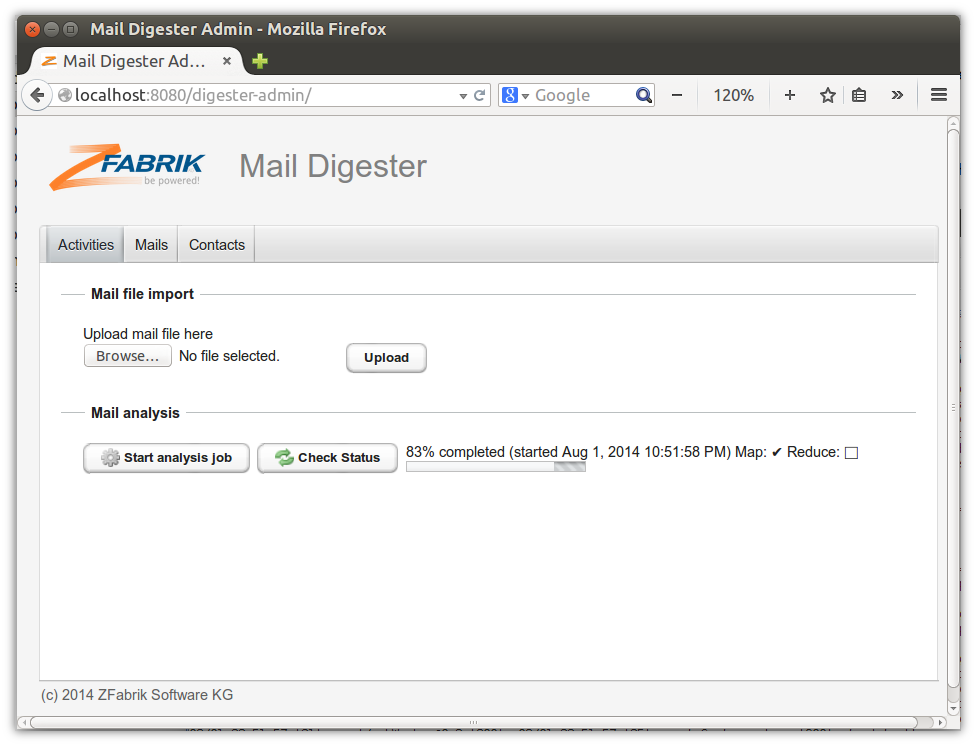
And work should be completed shortly after. When done, check the extracted sender data:
How this works¶
Let's go module by module in z2-samples-hbase-mail-digester
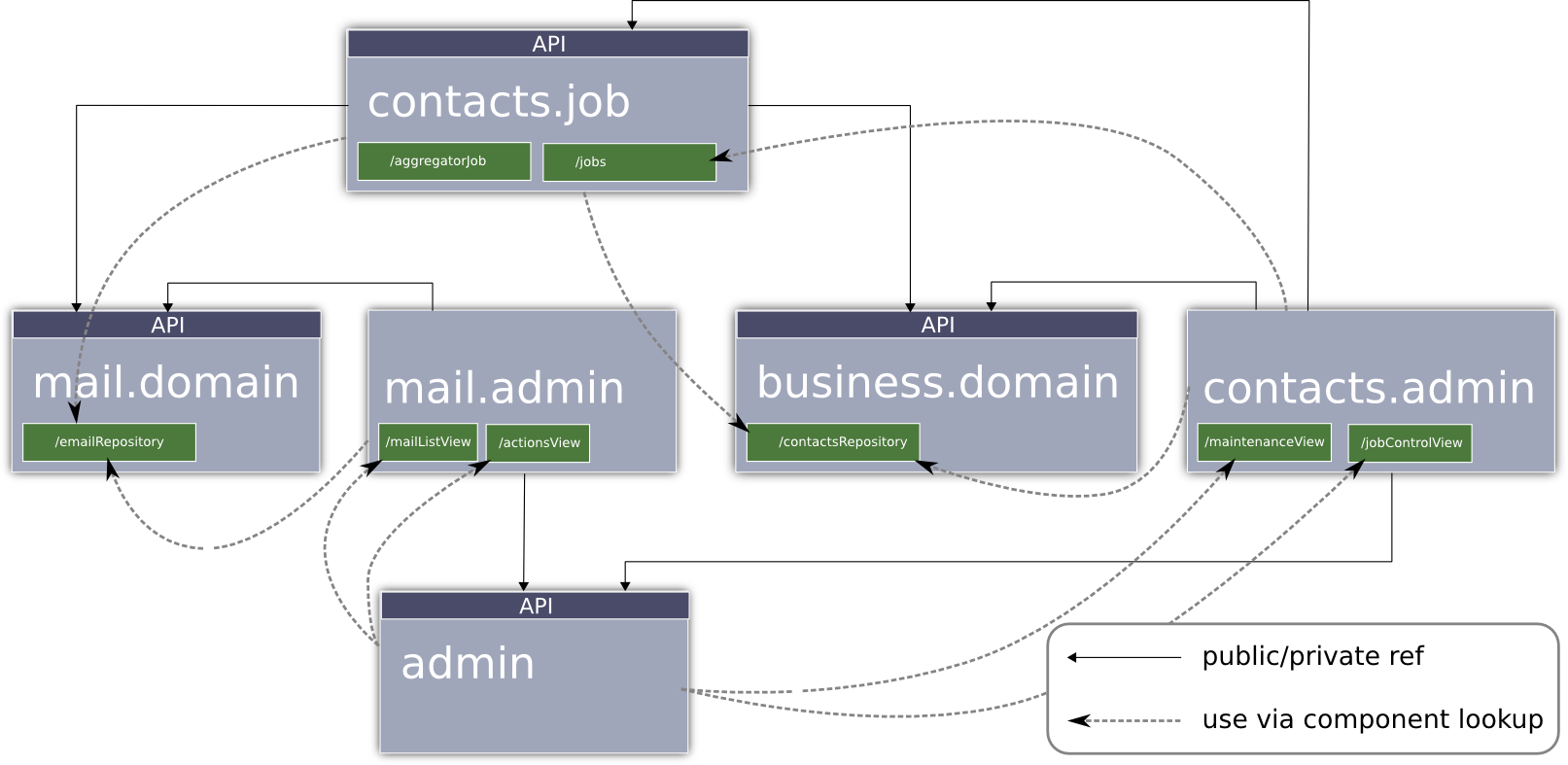
com.zfabrik.samples.digester.mail.domain¶
This modules defines data types and storage access for HBase stored e-mail messages. The interface EmailRepository is the main storage access interface. It's implementation can be found at EmailRepositoryImpl.
The Spring Bean HBaseConnector, used by the e-mail repository manages HBase connections.
com.zfabrik.samples.digester.mail.admin¶
This module defines the Mails tab that is loaded via an extension point (see Vaadin add-on for more details on what that is) from the main tab (defined in com.zfabrik.samples.digester.admin - below). Also it defines the Mail file import activity (another extension point). The Mails tab is defined via the component com.zfabrik.samples.digester.mail.admin/mailListView and the Mail file import activity via the component com.zfabrik.samples.digester.mail.admin/actionsView.
As this module interacts mainly with the e-mail repository, it imports it from com.zfabrik.samples.digester.mail.domain/emailRepository in its application context.
com.zfabrik.samples.digester.business.domain¶
This module defines the domain types and repositories for all relational data of the application or, more specifically, it defines the JPA entities for contacts and a JPA/Hibernate implemented repository for thoses. It's structure closely resembles those of for example sample-spring-hibernate.
com.zfabrik.samples.digester.contacts.admin¶
Similarly to com.zfabrik.samples.digester.mail.admin this module defines a main level tab Contacts and an activity Mail analysis in components com.zfabrik.samples.digester.contacts.admin/maintenanceView and com.zfabrik.samples.digester.contacts.admin/jobControlView respectively. The latter makes use of the ContactsJob service that allows to kick off an analysis map-reduce job and to retrieve job status information.
com.zfabrik.samples.digester.contacts.jobs¶
This module defines the ContactsJob service and the actual map-reduce job AggregatorJob.
The ContactsJob implementation interacts directly with Hadoop and the supporting function of Hadoop Addon to submit the map-reduce job and similarly to check its status. Note the (unfortunately necessary) careful class loader hygiene implemented by using ThreadUtil . See more in (Protecting Java in a Modular World – Context Classloaders) to learn about this necessity when using overly cleverly implemented class loader usage such as in Hadoop and HBase.
For the principles please check out how to hadoop. The mapper task AggregatorMapper is straight-forward: For every email message with sender S encountered emit (s.address, 1).
The combiner AggregatorCombiner simply sums counts up and implements
(s.address, o=(o_1, o_2, ...)) --> (s.address, sum(o_i,i))
At the heart of this sample's intention is the reducer AggregatorReducer.
Receiving a tuple (s.address, o=(o_1, o_2, ...)) it computes (s.address, sum(o_i,i))=:(a,t) and then updates a contact email count by looking for the contact entity identified by the email address a and then settings its mail count to t.
To do so it simply uses the ContactRepository that was Spring injected via the exact same module re-use as in the admin user interface modules – no difference here, although this is running on a hadoop data node.
Specifically in AggregatorReducer we use Spring AspectJ configuration:
@Configurable
public class AggregatorReducer extends Reducer<Text, IntWritable, Text, Writable> {
private int count;
@Autowired
private ContactsRepository contacts;
// ...
to inject a service that is reference in the module's application context as
<!-- import contacts repository -->
<bean id="contactsRepository" class="com.zfabrik.springframework.ComponentFactoryBean">
<property name="componentName" value="com.zfabrik.samples.digester.business.domain/contactsRepository" />
<property name="className" value="com.zfabrik.samples.digester.business.domain.ContactsRepository" />
</bean>
com.zfabrik.samples.digester.admin¶
This final module is the visual glue of the whole application. It defines the skeleton Vaadin application that loads all extension point implementations. This happens in AdminWindowWorkArea
// ...
// add all extensions
Collection<Component> exts = ExtensionComponentsUtil.getComponentyByExtensionForApplication(
AdminApplication.current(),
EXTENSION_POINT
);
for (Component c : exts) {
addTab(c);
}
// ...
for the top level tabs and very similarly in DigesterActions for the activities presented on the front tab:
// ...
// search for extensions and add them here
for (Component c : ExtensionComponentsUtil.getComponentyByExtensionForApplication(
AdminApplication.current(),
EXTENSION_POINT)
) {
addComponent(c);
}
// ...
The overview below summarizes module type reuse dependencies and cross-module component use (typically via application context import as above):
Updated by Henning Blohm over 10 years ago · 24 revisions