
The Hadoop add-on¶
The Hadoop add on actually contains the client parts of the Cloudera Hadoop and HBase distribution plus some integration features that are described in How to Hadoop and related samples.
It is provided via the repository z2-addons.hadoop.
As Hadoop and HBase do not have a clear client - server compatibility vector, you may only use the Hadoop add-on with a matching server version.
Version map¶
| add-on version | Hadoop/HBase version |
|---|---|
| 2.1 | CDH 4.0.1 |
We do - for experimental use only! - provide an easy to install and use, pre-configured single-node CDH 4.0.1 via the Git repository z2-samples.cdh4-base. The samples Sample-hadoop-basic and Sample-hbase-mail-digester make use of that. See Install prepacked CDH4 on how to set it up.
Extensions that help working with Hadoop are implemented by the modules com.zfabrik.hadoop and com.zfabrik.hbase.
Details on com.zfabrik.hadoop¶
Javadocs can be found here: Javadocs
Component type com.zfabrik.hadoop.configuration¶
Components of this type provide Hadoop or HBase connectivity configuration via a component resource file "core-site.xml". There is no further configuration applicable.
Component type com.zfabrik.hadoop.job¶
A Hadoop Map/Reduce job implementation. Using this component type, Jobs may be programmatically scheduled and run within the Z2 runtime.
Properties:
| Name | Value or Description |
|---|---|
| com.zfabrik.component.type | com.zfabrik.hadoop.job |
| component.className | The name of a class provided by the module that implements IMapReduceJob |
Details on com.zfabrik.hbase¶
This module provides additional utilities and types on top of com.zfabrik.hadoop that simplify and help working with HBase.
Javadocs can be found here: Javadocs
This module does not provide component types. It does however providing a narrowing interface IHBaseMapReduceJob that extends IMapReduceJob for Map/Reduce jobs over HBase tables.
See also Sample-hbase-mail-digester.
How does Map/Reduce with Z2 on Hadoop work¶
When preparing a job for execution by Hadoop, what actually happens is that Hadoop stores one or more jar libraries in HDFS. In order to run a map, reduce, or combine task, Hadoop downloads the libraries to the local node and runs the required task from code provided by the libraries.
When running a job with Z2's Hadoop integration this is no different. But instead of submitting the actual task implementations to Hadoop, a generic job library is provided to Hadoop. On the node executing a task, the generic task implementations (all here) start an embedded Z2 runtime (see ProcessRunner), in-process, look for the Job component that implements IMapReduceJob and delegate execution in context to the real implementation.
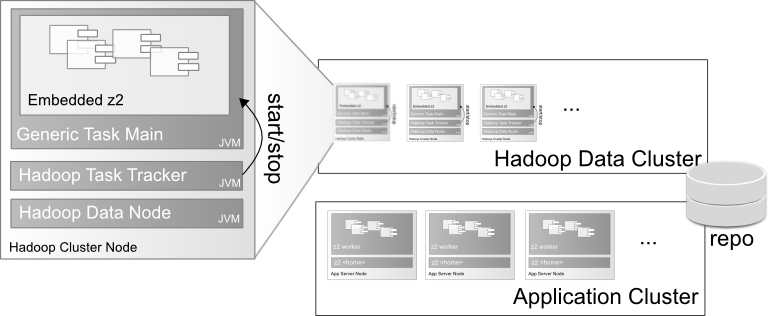
The one catch here is that z2 home must be available on the node running the task and it must be found by the generic implementation.
In the samples this is achieved by having the environment variable Z2_HOME point to the installation next to the Hadoop installation. In cluster setups, a Z2 core is part of the installables next to Hadoop, HBase, and others.
Only the core is required, as job updates will be retrieved from repositories automatically.
A true specialty of the sample setups is the use of the Dev Repo (see Workspace development using the Dev Repository). As the Dev Repo is controlled by system properties and as the Hadoop integration is aware of this use case, we can use the Hadoop client connection config (e.g. here) to also convey a Dev Repo scan root (so to say) which allows to run M/R jobs directly from the workspace - you might say.
How to support other Hadoop versions¶
TBD
Updated by Henning Blohm almost 12 years ago · 16 revisions